
Briefly
Veo 3.1 introduces full-scene audio, dialogue, and ambient sound era.
The launch follows Sora 2’s fast rise to 1 million downloads inside 5 days.
Google positions Veo as a professional-grade different within the crowded AI video market.
Google launched Veo 3.1 in the present day, an up to date model of its AI video generator that provides audio throughout all options and introduces new modifying capabilities designed to provide creators extra management over their clips.
The announcement comes as OpenAI’s competing Sora 2 app climbs app retailer charts and sparks debates about AI-generated content material flooding social media.
The timing suggests Google needs to place Veo 3.1 because the skilled different to Sora 2’s viral social feed method. OpenAI launched Sora 2 on September 30 with a TikTok-style interface that prioritizes sharing and remixing.
The app hit 1 million downloads inside 5 days and reached the highest spot in Apple’s App Retailer. Meta took an identical method, with its personal kind of digital social media powered by AI movies.
Customers can now create movies with synchronized ambient noise, dialogue, and Foley results utilizing “Substances to Video,” a device that mixes a number of reference photographs right into a single scene.
The “Frames to Video” function generates transitions between a beginning and ending picture, whereas “Prolong” creates clips lasting as much as a minute by persevering with the movement from the ultimate second of an present video.
New modifying instruments let customers add or take away parts from generated scenes with computerized shadow and lighting changes. The mannequin generates movies in 1080p decision at horizontal or vertical facet ratios.
The mannequin is accessible by Stream for shopper use, the Gemini API for builders, and Vertex AI for enterprise clients. Movies lasting as much as a minute will be created utilizing the “Prolong” function, which continues movement from the ultimate second of an present clip.
The AI video era market has turn into crowded in 2025, with Runway’s Gen-4 mannequin focusing on filmmakers, Luma Labs providing quick era for social media, Adobe integrating Firefly Video into Inventive Cloud, and updates from xAI, Kling, Meta, and Google focusing on realism, sound era, and immediate adherence.
However how good is it? We examined the mannequin, and these are our impressions.
Testing the mannequin
If you wish to strive it, you’d higher have some deep pockets. Veo 3.1 is presently the costliest video era mannequin, on par with Sora 2 and solely behind Sora 2 Professional, which prices greater than twice as a lot per era.
Free customers obtain 100 month-to-month credit to check the system, which is sufficient to generate round 5 movies monthly. By means of the Gemini API, Veo 3.1 prices roughly $0.40 per second of generated video with audio, whereas a sooner variant referred to as Veo 3.1 Quick prices $0.15 per second.
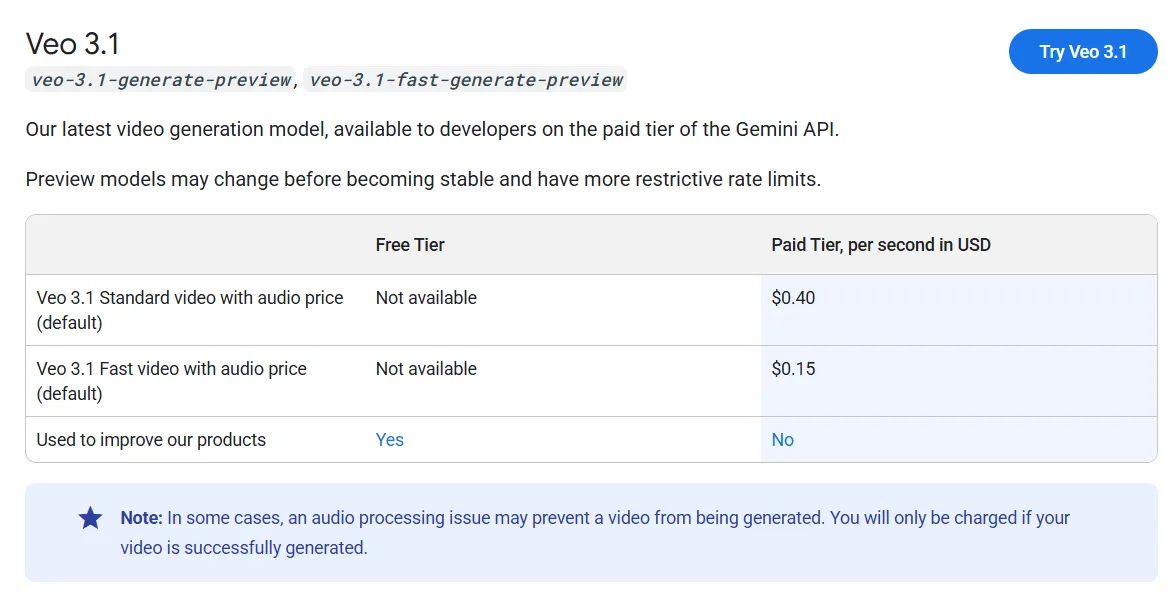
For these prepared to make use of it at that worth, listed here are its strengths and weaknesses.
Textual content to Video
Veo 3.1 is a particular enchancment over its predecessor. The mannequin handles coherence properly and demonstrates a greater understanding of contextual environments.
It really works throughout completely different kinds, from photorealism to stylized content material.
We requested the mannequin to mix a scene that began as a drawing and transitioned into live-action footage. It dealt with the duty higher than another mannequin we examined.
With none reference body, Veo 3.1 produced higher ends in text-to-video mode than it did utilizing the identical immediate with an preliminary picture, which was stunning.
The tradeoff is motion velocity. Veo 3.1 prioritizes coherence over fluidity, making it difficult to generate fast-paced motion.
Components transfer extra slowly however preserve consistency all through the clip. Kling nonetheless leads in fast motion, though it requires extra makes an attempt to attain usable outcomes.
Picture to Video
Veo constructed its status on image-to-video era, and the outcomes nonetheless ship—with caveats. This seems to be a weaker space within the replace. When utilizing completely different facet ratios as beginning frames, the mannequin struggled to take care of the coherence ranges it as soon as had.
If the immediate strays too removed from what would logically comply with the enter picture, Veo 3.1 finds a method to cheat. It generates incoherent scenes or clips that soar between areas, setups, or solely completely different parts.
This wastes time and credit, since these clips cannot be edited into longer sequences as a result of they do not match the format.
When it really works, the outcomes look implausible. Getting there may be half talent, half luck—largely luck.
Components to Video
This function works like inpainting for video, letting customers insert or delete parts from a scene. Do not count on it to take care of good coherence or use your actual reference photographs, although.
For instance, the video under was generated utilizing these three references and the immediate: a person and a lady come upon one another whereas operating in a futuristic metropolis, the place a Bitcoin signal hologram is rotating. The person tells the lady, “QUICK, BITCOIN CRASHED! WE MUST BUY MORE!!

As you possibly can see, neither town nor the characters are literally there. Nonetheless, characters are carrying the garments of reference, town resembles the one within the within the picture, and issues painting the thought of the weather, not the weather themselves.
Veo 3.1 treats uploaded parts as inspiration reasonably than strict templates. It generates scenes that comply with the immediate and embrace objects that resemble what you supplied, however do not waste time attempting to insert your self right into a film—it will not work.
A workaround: use Nanobanana or Seedream to add parts and generate a coherent beginning body first. Then feed that picture to Veo 3.1, which is able to produce a video the place characters and objects present minimal deformation all through the scene.
Textual content to Video with Dialogue
That is Google’s promoting level. Veo 3.1 handles lip sync higher than another mannequin presently out there. In text-to-video mode, it generates coherent ambient sound that matches scene parts.
The dialogue, intonation, voices, and feelings are correct and beat competing fashions.
Different turbines can produce ambient noise, however solely Sora, Veo, and Grok can generate precise phrases.
Of these three, Veo 3.1 requires the fewest makes an attempt to get good ends in text-to-video mode.
Picture to Video with Dialogue
That is the place issues collapse. Picture-to-video with dialogue suffers from the identical points as commonplace image-to-video era. Veo 3.1 prioritizes coherence so closely that it ignores immediate adherence and reference photographs.
For instance, this scene was generated utilizing the reference proven within the parts to video part.
As you possibly can see, our check generated a very completely different topic than the reference picture. The video high quality was glorious—intonation and gestures had been spot-on—but it surely wasn’t the particular person we uploaded, making the consequence ineffective.
Sora’s remix function is the only option for this use case. The mannequin could also be censored, however its image-to-video capabilities, real looking lip sync, and concentrate on tone, accent, emotion, and realism make it the clear winner.
Grok’s video generator is available in second. It revered the reference picture higher than Veo 3.1 and produced superior outcomes. Right here is one era utilizing the identical reference picture and immediate.
If you happen to do not need to cope with Sora’s social app or lack entry to it, Grok is perhaps the best choice. It is also uncensored however moderated, so in the event you want that specific method, Musk has you coated.
Usually Clever E-newsletter
A weekly AI journey narrated by Gen, a generative AI mannequin.







{kind=link}